Je vais être honnête : il y a quelques temps, le développement et les API, ce n’était pas vraiment ma tasse de thé. Mon terrain de jeu, c’était la console, le SSH, les commandes tapées à la volée.
Mais avec le blocage futur (et inéluctable) de l’accès SSH sur Prism Element et Prism Central, je n’ai pas eu le choix : il a fallu s’y mettre sérieusement.
Et quitte à plonger dans le monde des API Nutanix depuis mon PC Windows, autant le faire avec les bons outils pour ne pas s’arracher les cheveux. Dans cet article, je vous montre comment je me suis doté des outils parfaits pour interroger les API Nutanix.
Pourquoi optimiser son environnement Windows pour les API ?
Pendant des années, mon réflexe d’administrateur système face à une tâche complexe ou répétitive sur Nutanix a été le même : ouvrir PuTTY, me connecter en SSH à une Controller VM (CVM), et lancer des commandes ncli ou acli à la volée. C’était rapide, c’était efficace.
Mais je vais être direct : cette époque est révolue. Nutanix opère un virage sécuritaire majeur. L’accès SSH aux clusters sera désactivé dans l’une des prochaines versions, relégué au simple rang d’accès d’urgence pour le support. La seule méthode pérenne, supportée et évolutive pour interagir avec votre infrastructure, c’est l’API. Qu’il s’agisse de l’API v2 pour piloter un cluster local via Prism Element, ou des API v3 sur Prism Central, l’automatisation par API est devenue la norme.
Le problème ? Windows n’est historiquement pas le meilleur élève pour manipuler des requêtes web complexes en ligne de commande. PowerShell a fait d’énormes progrès avec Invoke-RestMethod, mais quand il s’agit de tester, débugger et formater du JSON imbriqué, rien ne remplace un socle Linux solide couplé à un client API graphique.
C’est là qu’entrent en jeu nos deux meilleurs alliés : WSL (Windows Subsystem for Linux) pour la puissance de la ligne de commande native, et Postman pour l’exploration visuelle des API Nutanix. Voyons comment mettre tout cela en musique.
Le socle système avec WSL (Windows Subsystem for Linux)
Comment éviter de s’arracher les cheveux avec les guillemets d’une commande curl sous l’invite de commande Windows (cmd) ou se battre avec l’échappement des caractères sous PowerShell ? La solution la plus élégante et robuste aujourd’hui est d’utiliser le sous-système Windows pour Linux (WSL).
Déployer WSL et Ubuntu en quelques minutes
L’installation est ultra simple sur les versions récentes de Windows 10 et 11. Ouvrez une console PowerShell en tant qu’administrateur et tapez simplement cette commande magique :
wsl --install ubuntu
Puis redémarrez votre PC. Vous avez maintenant une distribution Ubuntu fonctionnelle, totalement intégrée à votre Windows, sans la lourdeur d’une machine virtuelle classique. C’est l’environnement parfait pour faire tourner vos futurs scripts Bash ou Python ciblant l’infrastructure Nutanix.
Cherchez l’icone “Ubuntu” dans le menu démarrer de Windows pour lancer l’invite de commande sur le sous système.
Les paquets indispensables : curl et jq
Une fois dans votre nouveau terminal Ubuntu, il vous manque deux outils vitaux pour dialoguer avec les API REST : curl (le standard pour forger les requêtes web) et jq (le couteau suisse absolu pour manipuler, filtrer et formater les réponses JSON). Installez-les avec ces lignes de commande :
sudo apt update && sudo apt upgrade
sudo apt install curl jq -y
Pourquoi jq est-il si critique dans notre métier ? Laissez-moi vous partager une situation concrète du terrain. Les réponses JSON renvoyées par Prism Element ou Prism Central sont souvent extrêmement verbeuses. Si je veux simplement récupérer l’identifiant unique (UUID) de mon cluster via l’API v2 pour l’utiliser dans un script, sans me noyer dans des centaines de lignes de configuration, voici la commande exacte que j’utilise :
curl -k -u admin:MonMotDePasse -X GET https://<VOTRE_IP_PRISM_ELEMENT>:9440/api/nutanix/v2.0/cluster | jq '.cluster_uuid'
Le paramètre -k est crucial ici : il ignore l’avertissement de certificat SSL (qui est auto-signé par défaut sur Nutanix), et le | jq '.cluster_uuid' filtre instantanément la réponse brute pour ne me retourner que l’information ciblée (dans l’exemple ci dessous : "00064a67-579d-c757-5883-002590b8ef5a"). C’est propre, net, et parfaitement intégrable dans une variable pour automatiser un workflow de déploiement par exemple.
Le client API graphique incontournable : Postman
La ligne de commande, c’est génial pour exécuter des scripts de production. Mais quand il faut explorer une nouvelle API, tester les paramètres d’une requête complexe ou analyser la structure d’un payload JSON de 500 lignes, je préfère une interface graphique. Et dans ce domaine, Postman est parfaitement indiqué. Vous pouvez le télécharger et l’installer en quelques secondes depuis leur site officiel.
Configurer son premier environnement de travail
La première erreur que j’ai commise en débutant avec l’API Nutanix (et avec Postman en général), c’est de coder en dur mes adresses IP, mes usernames et mes mots de passe dans chaque requête. Ne faites jamais ça ! Non seulement c’est fastidieux si vous changez de cluster, mais c’est surtout un risque majeur de fuite d’informations si vous partagez votre écran ou vos collections.
Postman propose une fonctionnalité vitale : les Environnements. Créez un nouvel environnement (par exemple « Cluster de Prod ») et définissez-y trois variables :
cluster_ip : L’adresse IP de votre Prism Element ou Prism Central.username : Votre compte de service (évitez d’utiliser le compte admin par défaut si possible).password : Le mot de passe associé (à configurer en type « Secret » pour le masquer).
Désormais, dans vos requêtes, vous n’utiliserez plus l’URL brute, mais l’appel aux variables entre doubles accolades : https://{{cluster_ip}}:9440/api/nutanix/v2.0/...
L’astuce de l’expert : Importer le Swagger de Prism Central
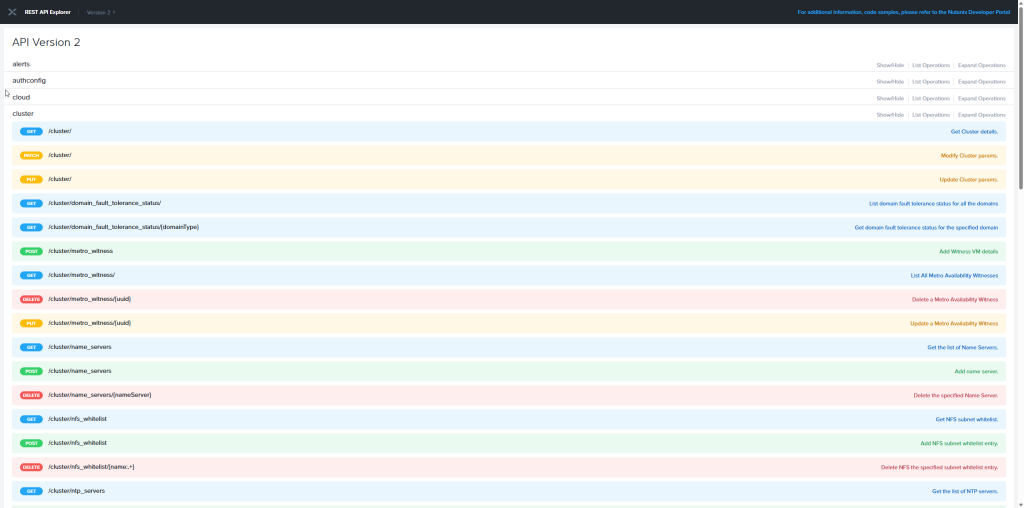
Voici ma véritable astuce » pour vous faire gagner des heures. Les API Nutanix, particulièrement les API v3 sur Prism Central, sont extrêmement vastes. Plutôt que de créer vos requêtes GET, POST ou PUT une par une en lisant laborieusement la documentation sur le portail Nutanix.dev, saviez-vous que vous pouviez aspirer toute la configuration directement depuis votre propre cluster ?
L’API de Prism Central expose sa spécification OpenAPI (Swagger). Dans Postman, cliquez sur le bouton « File > Import » dans le menu en haut à gauche, choisissez « Link », et collez simplement cette URL (en remplaçant l’IP par celle de votre Prism Central) : https://<PRISM_CENTRAL_IP>:9440/static/v3/swagger.json
Laissez la magie opérer : Postman va interroger votre cluster et générer automatiquement une Collection complète contenant absolument toutes les requêtes API v3 possibles, préformatées avec les bons headers et les payloads d’exemple. C’est un gain de temps monstrueux pour l’exploration !
Test : Le premier Call API depuis Postman
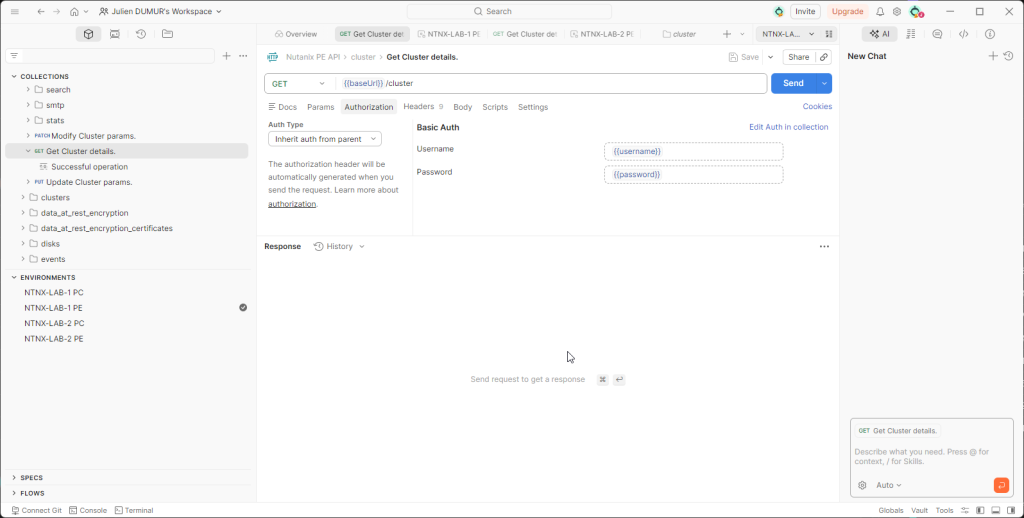
Maintenant que l’outillage est prêt et que mes variables sont configurées. Il est temps de faire la première requête graphique vers le cluster pour récupérer ses informations globales.
Gérer l’authentification et contourner le piège du SSL
Créez une nouvelle requête dans Postman (bouton + ou New > HTTP Request). Sélectionnez la méthode GET et entrez l’URL suivante en utilisant notre variable : https://{{cluster_ip}}:9440/api/nutanix/v3.0/cluster
Avant de cliquer sur « Send », il nous reste deux réglages à réaliser :
- L’authentification : Allez dans l’onglet Authorization, choisissez le type Basic Auth. Dans les champs Username et Password, tapez respectivement
{{username}} et {{password}}. Postman remplacera ces valeurs à la volée.
- Le certificat SSL : Par défaut, Nutanix utilise des certificats auto-signés. Si vous lancez la requête maintenant, Postman va bloquer l’appel avec une erreur de sécurité. Allez dans File > Settings (ou l’icône engrenage), onglet General, et désactivez l’option « SSL certificate verification ». C’est l’équivalent graphique de notre paramètre
-k dans curl.
Cliquez sur Send. Si tout est vert (Status 200 OK), vous devriez voir apparaître en bas un magnifique JSON formaté, contenant l’UUID de votre cluster, son nom, sa version d’AOS et ses adresses virtuelles. Bravo, votre poste de travail communique avec Nutanix !
Basic Auth vs JSESSIONID
Si vous débutez, la méthode Basic Auth (qui envoie vos identifiants à chaque requête) est parfaite. Mais attention : cette méthode a un impact.
Pourquoi ? Parce qu’à chaque fois que vous faites un appel API en Basic Auth, le service Acropolis de la CVM doit valider vos identifiants auprès du module d’authentification (et souvent, ces identifiants seront lié à un Active Directory via LDAP). Si vous lancez un script qui fait 500 requêtes d’affilée pour inventorier des VMs, vous allez déclencher 500 validations d’identité. Cela sature inutilement les CVMs et vos contrôleurs de domaine.
La bonne pratique si vous scriptez massivement : Authentifiez-vous une seule fois, et utilisez les Cookies de session ! Lorsque vous faites une première requête d’authentification ou que vous interrogez l’API, Nutanix vous renvoie un cookie nommé JSESSIONID. Postman le stocke automatiquement et l’utilise pour les requêtes suivantes de votre collection. Dans vos futurs scripts Bash/Python, pensez toujours à récupérer ce cookie lors du premier appel, et passez-le dans les Headers de vos appels suivants. Vous soulagerez drastiquement le management plane de votre cluster !
Conclusion : Rappel de sécurité et utilisation avancée
Tous les outils sont désormais en place pour s’affranchir au maximum du SSH lors de mes prochaines sessions troubleshooting.
Je dois faire un rappel de sécurité fondamental. Postman permet d’exporter vos collections pour les partager avec vos collègues ou les sauvegarder. C’est génial pour le travail en équipe. Mais attention : si vous n’avez pas utilisé les variables d’environnement comme nous l’avons vu précédemment, et que vous avez tapé vos mots de passe « en dur » directement dans l’onglet Authorization de vos requêtes, ils seront exportés en clair dans le fichier JSON de la collection.
Assurez-vous toujours que vos « Secrets » restent dans votre configuration d’Environnement locale (qui, par défaut, n’exporte pas les valeurs actuelles avec la collection). J’ai vu trop de mots de passe d’administration traîner sur le réseau à cause de ça !
Maintenant, il ne me reste plus qu’à me pencher sur la partie scripting et automatisation afin de pouvoir développer des applications qui m’aideront à piloter, auditer et configurer mes clusters Nutanix.
Mais ça, ce sera le sujet d’un prochain article ! D’ici là, bonnes requêtes à tous.